RabbitMQ Overview¶
# NOTE: Some of the RabbitMQ summary/overview documentation and supporting images added here are taken from RabbitMQ official documentation.
RabbitMQ is the most popular messaging library with over 35,000 production deployments. It is highly scalable, easy to deploy, runs on many operating systems and cloud environments. It supports many kinds of distributed deployment methodologies such as clusters, federation and shovels.
RabbitMQ uses Advanced Message Queueing Protocol (AMQP) and works on the basic producer consumer model. A consumer is a program that consumes/receives messages and producer is a program that sends the messages. Following are some important definitions that we need to know before we proceed.
Queue - Queues can be considered like a post box that stores messages until consumed by the consumer. Each consumer must create a queue to receives messages that it is interested in receiving. We can set properties to the queue during it’s declaration. The queue properties are
- Name - Name of the queue
- Durable - Flag to indicate if the queue should survive broker restart.
- Exclusive - Used only for one connection and it will be removed when connection is closed.
- Auto-queue - Flag to indicate if auto-delete is needed. The queue is deleted when last consumer un-subscribes from it.
- Arguments - Optional, can be used to set message TTL (Time To Live), queue limit etc.
Bindings - Consumers bind the queue to an exchange with binding keys or routing patterns. Producers send messages and associate them with a routing key. Messages are routed to one or many queues based on a pattern matching between a message routing key and binding key.
Exchanges - Exchanges are entities that are responsible for routing messages to the queues based on the routing pattern/binding key used. They look at the routing key in the message when deciding how to route messages to queues. There are different types of exchanges and one must choose the type of exchange depending on the application design requirements
Fanout - It blindly broadcasts the message it receives to all the queues it knows.
Direct - Here, the message is routed to a queue if the routing key of the message exactly matches the binding key of the queue.
Topic - Here, the message is routed to a queue based on pattern matching of the routing key with the binding key. The binding key and the routing key pattern must be a list of words delimited by dots, for example, “car.subaru.outback” or “car.subaru.*”, “car.#”. A message sent with a particular routing key will be delivered to all the queues that are bound with a matching binding key with some special rules as
‘*’ (star) - can match exactly one word in that position. ‘#’ (hash) - can match zero or more words
Headers - If we need more complex matching then we can add a header to the message with all the attributes set to the values that need to be matched. The message is considered matching if the values of the attributes in the header is equal to that of the binding. Header exchange ignore the routing key.
We can set some properties to the exchange during it’s declaration.
- Name - Name of the exchange
- Durable - Flag to indicate if the exchange should survive broker restart.
- Auto-delete - Flag indicates if auto-delete is needed. If set to true, the exchange is deleted when the last queue is unbound from it.
- Arguments - Optional, used by plugins and broker-specific features
Lets use an example to understand how they all fit together. Consider an example where there are four consumers (Consumer 1 - 4) interested in receiving messages matching the pattern “green”, “red” or “yellow”. In this example, we are using a direct exchange that will route the messages to the queues only when there is an exact match of the routing key of the message with the binding key of the queues. Each of the consumers declare a queue and bind the queue to the exchange with a binding key of interest. Lastly, we have a producer that is continuously sending messages to exchange with routing key “green”. The exchange will check for an exact match and route the messages to only Consumer 1 and Consumer 3.
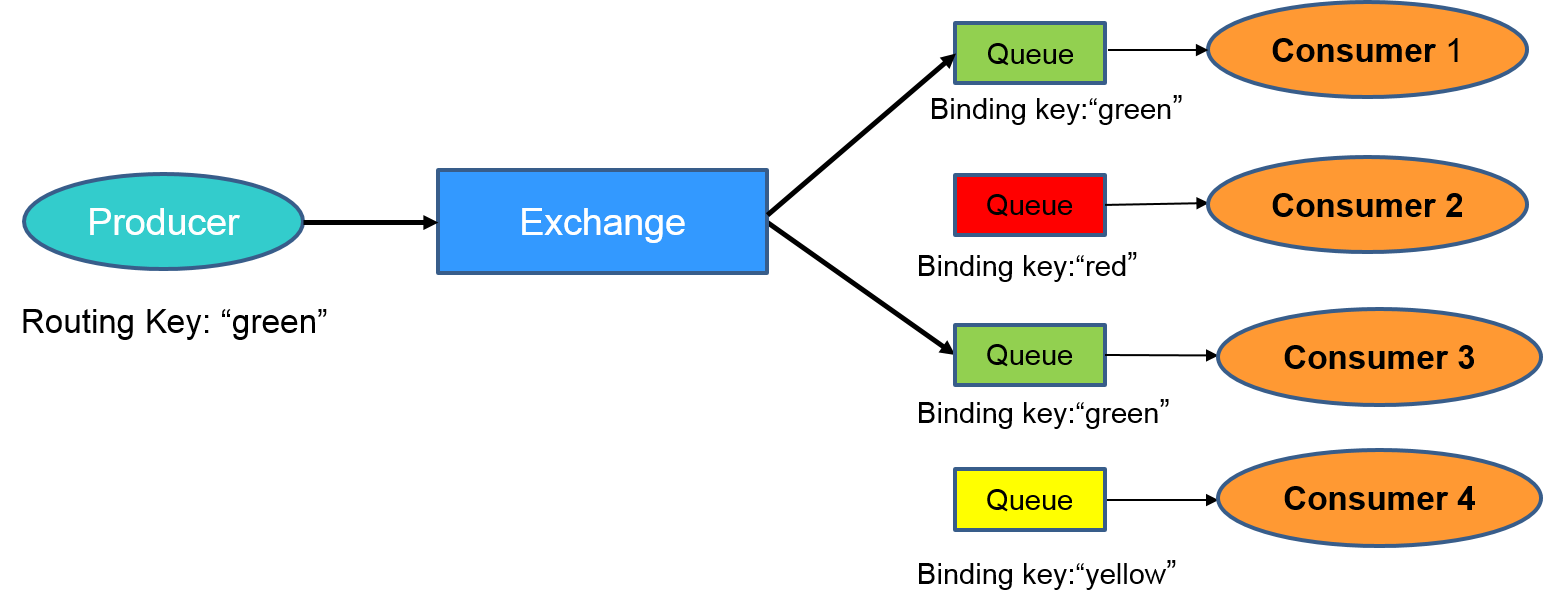
For more information about queues, bindings, exchanges, please refer to RabbitMQ tutorial.
Distributed RabbitMQ Brokers¶
RabbitMQ allows multiple distributed RabbitMQ brokers to be connected in three different ways - with clustering, with federation and using shovel. We take advantage of these built-in plugins for multi-platform VOLTTRON communication. For more information about the differences between clustering, federation, and shovel, please refer to RabbitMQ documentation Distributed RabbitMQ brokers.
Clustering¶
Clustering connects multiple brokers residing in multiple machines to form a single logical broker. It is used in applications where tight coupling is necessary i.e, where each node shares the data and knows the state of all other nodes in the cluster. A new node can connect to the cluster through a peer discovery mechanism if configured to do so in the RabbitMQ config file. For all the nodes to be connected together in a cluster, it is necessary for them to share the same Erlang cookie and be reachable through it’s DNS hostname. A client can connect to any one of the nodes in the cluster and perform any operation (to send/receive messages from other nodes etc.), the nodes will route the operation internally. In case of a node failure, clients should be able to reconnect to a different node, recover their topology and continue operation.
Please note, this feature is not integrated into VOLTTRON. But we hope to support it in the future. For more detailed information about clustering, please refer to RabbitMQ documentation Clustering plugin.
Federation¶
Federation plugin is used in applications that does not require as much of tight coupling as clustering. Federation has several useful features.
- Loose coupling - The federation plugin can transmit messages between brokers (or clusters) in different administrative domains:
- they may have different users and virtual hosts;
- they may run on different versions of RabbitMQ and Erlang.
- WAN friendliness - They can tolerate network intermittent connectivity.
- Specificity - Not everything needs to be federated ( made available to other brokers ). There can be local-only components.
- Scalability - Federation does not require O(n2) connections for n brokers, so it scales better.
The federation plugin allows you to make exchanges and queues federated. A federated exchange or queue can receive messages from one or more upstreams (remote exchanges and queues on other brokers). A federated exchange can route messages published upstream to a local queue. A federated queue lets a local consumer receive messages from an upstream queue.
Before we move forward, let’s define upstream and downstream servers.
- Upstream server - The node that is publishing some message of interest
- Downstream server - The node connected to a different broker that wants to receive messages from the upstream server
A federation link needs to be established from downstream server to the upstream server. The data flows in single direction from upstream server to downstream server. For bi-directional data flow, we would need to create federation links on both the nodes.
We can receive messages from upstream server to downstream server by either making an exchange or a queue federated.
For more detailed information about federation, please refer to RabbitMQ documentation Federation plugin.
Federated Exchange¶
When we make an exchange on the downstream server federated, the messages published to the upstream exchanges are copied to the federated exchange, as though they were published directly to it.
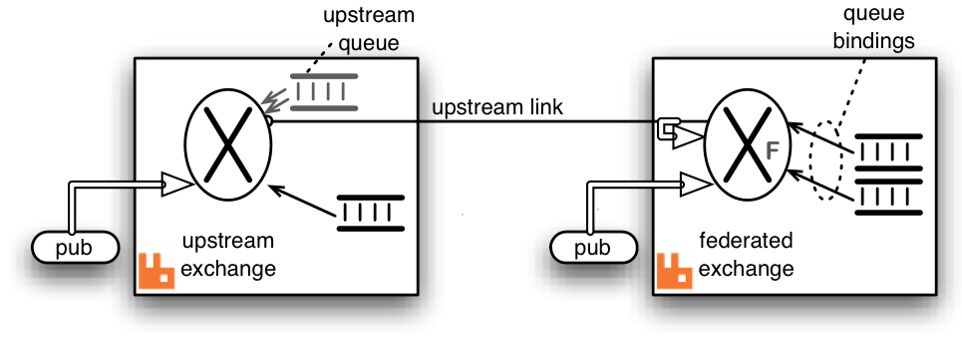
Above figure explains message transfer using federated exchange. The box on the right acts as the downstream server and the box on the left acts as the upstream server. A federation/upstream link is established between the downstream server and the upstream server by using federation management plugin. An exchange on the downstream server is made federated using federation policy configuration. The federated exchange only receives the messages for which it has subscribed for. An upstream queue is created on the upstream server with a binding key same as subscription made on the federated exchange. For example, if an upstream server is publishing messages with binding key “foo” and a client on the downstream server is interested in receiving messages of the binding key “foo”, then it creates a queue and binds the queue to the federated with the same binding key. This binding is sent to the upstream and the upstream queue binds to the upstream exchange with that key.
Publications to either exchange may be received by queues bound to the federated exchange, but publications directly to the federated exchange cannot be received by queues bound to the upstream exchange.
For more information about federated exchanges and different federation topologies, please read Federated Exchanges.
Federated Queue¶
Federated queue provides a way of balancing load of a single queue across nodes or clusters. A federated queue lets a local consumer receive messages from an upstream queue. A typical use would be to have the same “logical” queue distributed over many brokers. Such a logical distributed queue is capable of having higher capacity than a single queue. A federated queue links to other upstream queues.
A federation or upstream link needs to be created like before and a federated queue needs to be setup on the downstream server using federation policy configuration. The federated queue will only retrieve messages when it has run out of messages locally, it has consumers that need messages, and the upstream queue has “spare” messages that are not being consumed.
For more information about federated queues, please read Federated Queues.
Shovel¶
Shovel plugin allows you to reliably and continually move messages from a source in one broker to destination in another broker. A shovel behaves like a well-written client application, that
- connects to it’s source and destination broker
- consumes messages from the source queue
- re-publishes messages to the destination if the messages match the routing key.
Shovel plugin uses Erlang client under the hood. In case of shovel, apart from configuring the hostname, port and virtual host of the remote node, we will also have to provide list of routing keys that we want to forward to remote node.The primary advantages of shovels are
- Loose coupling - A shovel can move messages between brokers (or clusters) in different administrative domains:
- they may have different users and virtual hosts;
- they may run on different versions of RabbitMQ and Erlang.
- WAN friendliness - They can tolerate network intermittent connectivity.
Shovels are also useful in case if one of the nodes is behind NAT. We can setup shovel on the node behind NAT to forward messages to the node outside NAT. Shovels do not allow you to adapt to subscriptions like a federation link and we need to a create a new shovel per subscription.
For more detailed information about shovel, please refer to RabbitMQ documentation Shovel plugin.
Authentication in RabbitMQ¶
By default RabbitMQ supports SASL PLAIN authentication with user name and password. RabbitMQ supports other SASL authentication mechanism using plugins. In VOLTTRON we use one such external plugin based on x509 certifcates(https://github.com/rabbitmq/rabbitmq-auth-mechanism-ssl). This authentication is based on a techique called public key cryptography which consists of a key pair - a public key and a private key. Data that has been encrypted with a public key can only be decrypted with the corresponding private key and vice versa. The owner of key pair makes the public key available and keeps the private confidential. To send a secure data to a receiver, a sender encrypts the data with the receiver’s public key. Since only the receiver has access to his own private key only the receiver can decrypted. This ensures that others, even if they can get access to the encrypted data, cannot decrypt it. This is how public key cryptography achieves confidentiality.
Digital certificate is a digital file that is used to prove ownership of a public key. Certificates act like identification cards for it owner/entity. Certificates are hence crucial to determine that a sender is using the right public key to encrypt the data in the first place. Digital Certificates are issued by Certification Authorities(CA). Certification Authorities fulfil the role of the Trusted Third Party by accepting Certificate applications from entities, authenticating applications, issuing Certificates and maintaining status information about the Certificates issued. Each CA has its own public private key pair and its public key certificate is called a root CA certificate. The CA attests to the identity of a Certificate applicant when it signs the Digital Certificate using its private key. In x509 based authentication, a signed certificate is presented instead of username/password for authentication and if the server recognizes the the signer of the certificate as a trusted CA, accepts and allows the connection. Each server/system can maintain its own list of trusted CAs (i.e. list of public certificates of CAs). Certificates signed by any of the trusted CA would be considered trusted. Certificates can also be signed by intermediate CAs that are in turn signed by a trusted.
This section only provides a breif overview about the SSL based authentication. Please refer to the vast material available online for detailed description. Some useful links to start:
Management Plugin¶
The rabbitmq-management plugin provides an HTTP-based API for management and monitoring of RabbitMQ nodes and clusters, along with a browser-based UI and a command line tool, rabbitmqadmin. The management interface allows you to
- Create, Monitor the status and delete resources such as virtual hosts, users, exchanges, queues etc.
- Monitor queue length, message rates and connection information and more
- Manage users and add permissions (read, write and configure) to use the resources
- Manage policies and runtime parameters
- Send and receive messages (for trouble shooting)
For more detailed information about the management plugin, please refer to RabbitMQ documentation Management Plugin.